先解释几个概念
机器学习主要分为:监督学习和无监督学习。
· 监督学习:从已知类别的数据集中学习出一个函数,这个函数可以对新的数据集进行预测或分类,数据集包括特征值和目标值,即有标准答案;常见算法类型可以分为:分类和回归。
分类问题常见算法:K-近邻(KNN)、朴素贝叶斯、决策树、随机森林、逻辑回归、神经网络 回归常用于预测,比如房价,常见算法:线性回归、岭回归
· 无监督学习:与监督学习的主要区别是,数据集中没有人为标注的目标值,即没有标准答案;常见算法有:聚类,生成对抗网络。
K-近邻算法
这是机器学习中最简单的一个算法,先看定义
定义:如果一个样本与特征空间中的K个样本距离最近,这K个样本中的大多数属于A类别,那么该样本也属于A类别。
通俗说就是通过你最近的K个邻居来求出你的类别; 比如现在要求你所在的区域,A在朝阳区,B在海淀区,C在海淀区,D在房山区,你与ABC的距离分别是:20,28,23,35;K值取3,那么这三个离你最近的邻居是A、B、C,这三个中有两个属于海淀区,按照K-近邻算法,你所在的区域就是海淀区;如果K取1,就是朝阳区; 由此也说明了K近邻算法的结果很大程度上受K取值的影响,通常K值取不大于20的整数。
K-近邻中的距离如何计算?
这里的距离一般使用欧式距离,公式如下:
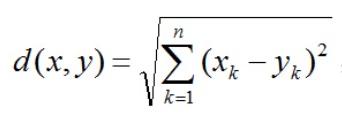
比如有两个样本:A (a1,a2,a3) ,B (b1,b2,b3)这两个样本的距离计算为:
从公式中可以看出,如果特征a1是体重,a2是身高,那么这两个特征的单位不同,而且a2的数值较大,对于结果的影响也较大,所以使用K-近邻算法之前需要对数据进行标准化(所有涉及到距离运算的算法都需要进行标准化),标准化的概念介绍在这里:
K-近邻的优缺点及应用场景
- 优点:易实现,无需估计参数,无需训练,对异常值不敏感
- 缺点:计算量大,耗内存,对K值依赖较大
- 适合数值型的小数据场景
scikit-learn中K-近邻的API是:sklearn.neighbors.KNeighborsClassifier
下面结合scikit-learn中的内置数据集(鸢尾花数据集),介绍scikit-learn中K-近邻的简单使用:
# scikit-learn中的内置数据集都在datasets这个模块中,导入鸢尾花数据集from sklearn.datasets import load_iris# 导入K-近邻的APIfrom sklearn.neighbors import KNeighborsClassifier# 导入标准化APIfrom sklearn.preprocessing import StandardScaler# 导入切分数据集的APIfrom sklearn.model_selection import train_test_split# 加载数据iris = load_iris()# 切分数据集,参数含义下面详解x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.25,random_state=None)
train_testsplit用于将数据集切分为训练集和测试集,训练集用于模型的训练,测试集用于模型的验证; 第一个参数是特征值,第二个参数是目标值; test_size用于设置测试集,如果是float类型,表示测试集的比例,一般取值为0.25,如果是int类型,表示测试集的个数;返回值分别是:训练集特征值,测试集特征值,训练集目标值,测试集目标值,这里用x表示特征值,y表示目标值; random_state是随机状态,默认为None,即没有固定的状态,会随机打散数据,每次运行返回的测试集和训练集都不同,如果是int类型,就代表该组随机数的编号,例如每次运行都设置为1,那么得出的数据集是相同的;
# 对训练集和测试集的特征值进行标准化std = StandardScaler()x_train = std.fit_transform(x_train)x_test = std.transform(x_test)# 实例化K近邻算法,算法实例化时需要手动指定的参数称为超参数,n_neighbors就是上面说的K值knn = KNeighborsClassifier(n_neighbors=3)# 将训练集放入模型进行训练knn.fit(x_train,y_train)# 使用测试集的特征值进行预测,返回预测的目标值y_predict = knn.predict(x_test)# 输入测试集的特征值和目标值进行评估print('准确率为:')knn.score(x_test,y_test) knn.score用于评估模型的准确率
输出结果:
准确率为: 0.9473684210526315
到这里已经介绍了scikit-learn中KNN的使用,但是上面构建的模型很有局限性,上面说过KNN的结果受K值影响,以上例子只进行了一次测试,并不知道此K值是不是最合适的,而且数据集只进行了一次切分,通常K-近邻需要搭配(K-折)交叉验证与网格搜索一起使用
什么是K-折交叉验证?
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
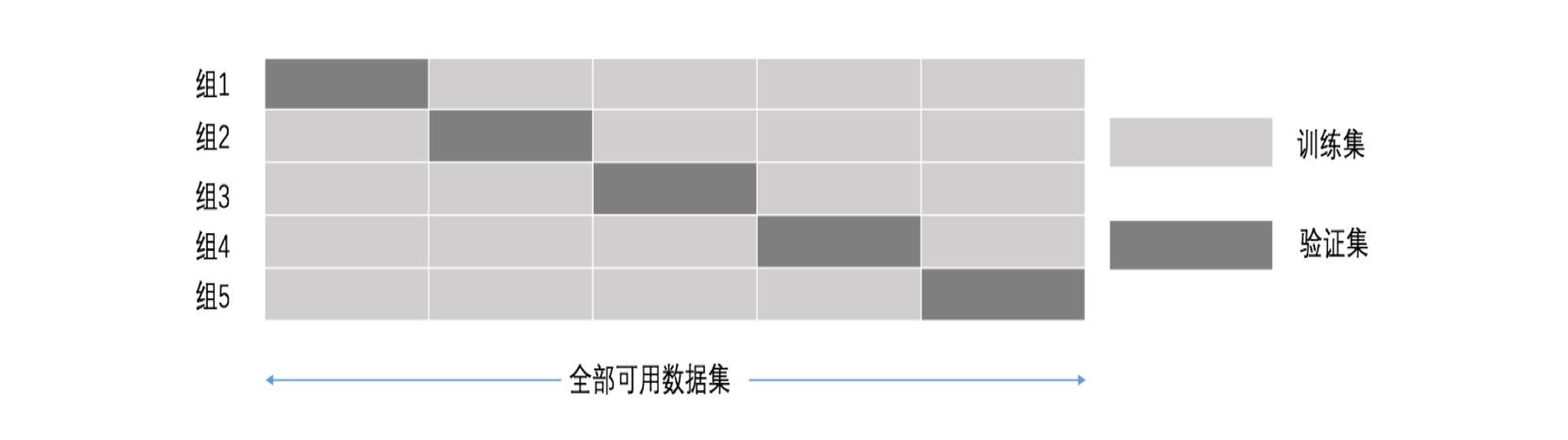
例如5折交叉验证,全部可用数据集分成五个集合,每次迭代都选其中的1个集合数据作为验证集,另外4个集合作为训练集,经过5组的迭代过程。交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现的更加可信,避免过拟合。
什么是网格搜索?
通过遍历给定的参数组合,选出最优的参数建立模型。
网格搜索的API是:sklearn.model_selection.GridSearchCV,里面实现了交叉验证
将以上例子结合网格搜索优化如下:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split,GridSearchCVfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.preprocessing import StandardScaler# 加载数据iris = load_iris()# 数据集切分x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.25,random_state=None)# 标准化处理std = StandardScaler()x_train = std.fit_transform(x_train)x_test = std.transform(x_test)knn = KNeighborsClassifier()# 构造一些参数的值进行搜索param_grid = { "n_neighbors": [3, 5, 10]}# 进行网格搜索gc = GridSearchCV(knn,param_grid=param_grid,cv=2)
GridSearchCV的第一个参数是估计器对象;param_grid是估计器参数;cv指几折交叉验证,这里使用2折
# 训练模型gc.fit(x_train,y_train)print("选择最好的模型是:", gc.best_estimator_)print("在测试集上准确率:", gc.score(x_test, y_test))
输出结果:
选择最好的模型是: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights='uniform')在测试集上准确率: 0.9473684210526315
从输出结果最好的模型可以看出,n_neighbors的值为5,模型最优。
总结,主要介绍了:
1、K-近邻算法的思想及其中的距离运算;
2、模型调优:网格搜索与交叉验证;